
Veri madenciliği nasıl çalışır?
Her alışveriş yaptığınızda, arkanızda bir iz bırakırsınız. Aynı şekilde, internette gezinirken fitness takipçinizi açın (yeni sekmede açılır) veya bankanıza kredi başvurusunda bulunun. Aslında, ona dokunabilseydik, onu boğacaktık. IBM'e göre (opens in new tab) her gün ürettiğimiz verinin toplamı akıl almaz bir 2,5 kentilyon bayta ulaşıyor ('25'in ardından 17 sıfır geliyor). O kadar hızlı üretiyoruz ki, şu anda dünyadaki verilerin tahmini %90'ı sadece son iki yılda oluşturuldu. Bu "Büyük Veri", milyarlarca dolar değerinde küresel bir kaynaktır ve her işletme ve hükümet, bunu ele geçirmek ister - hem de bunun iyi bir nedeni vardır.
Veriler, günlük hayatımızın dijital tarihidir - seçimlerimiz, satın almalarımız, kiminle konuştuğumuz, nereye gittiğimiz ve ne yaptığımız. Daha önce Nesnelerin İnterneti'ne (yeni sekmede açılır) (IoT) ve 'yaygın bilgi işlemin' yaşam biçimimizi nasıl kökten değiştireceğine baktık . IoT'nin veri oluşturma ve yakalamada daha da büyük bir patlamaya yol açacağını garanti edebilirsiniz - bulut depolama alanındaki patlama sayesinde, bu tür şeyleri elimizden geldiğince hızlı bir şekilde ortadan kaldırıyoruz.
Ancak veriler kendi başına oldukça işe yaramaz - olası terör tehditlerine karşı hükümetleri önceden uyarmak, bir dahaki sefere yerel meyve-sebzeden muhtemelen ne alacağınızı tahmin etmek için her şeyi yapabilen verilerden çıkardığımız bilgilerdir. Mevcut veri hacmi, yalnızca insanın deşifre etme yeteneğinin çok ötesindedir ve onu işlemek için bilgisayar işlemeye ihtiyaç duyar - 'veri madenciliği' kavramı burada devreye girer.
Makine öğrenme

Aslında, 'veri madenciliği', kendisi de Yapay Zekanın (AI) bir dalı olan 'makine öğrenimi' adı verilen büyüleyici bir bilgi işlem alanı için gerçekten moda bir kelimedir. Burada bilgisayarlar, dağlarca veriyi işlemek ve bunlardan bilgi üretmek veya "öğrenmek" için özel kod işlevleri veya "algoritmalar" kullanır.
İlk olarak 250 yıldan daha uzun bir süre önce keşfedilen matematiksel teknikleri de içeren, şu anda çığır açan bir araştırma alanı.
Bir açıdan, veri madenciliği, mahremiyet ve verilerden çıkarılan bilgilerin nasıl kullanıldığı konusunda artan etik kaygılarla birlikte, üzerinde biraz gölge bırakıyor. Ancak hepsi 'terör entrikaları ve alışveriş arabaları' değil – veri madenciliği, bilimler tarafından hava durumu tahmininden meme kanserinin nüksetmesini tahmin etmek ve diyabet başlangıcına ilişkin göstergeler bulmak için kullanıldığı tıbbi araştırmalara kadar her şey için yoğun bir şekilde kullanılıyor.
Stanford Üniversitesi'nin Folding@Home (yeni sekmede açılır) hastalık araştırma projesi, kansere, Parkinson hastalığına ve Alzheimer'a çareler arayarak dahil olabileceğiniz küresel ölçekte bir veri madenciliğidir.
Temelde makine öğrenimi, verilerdeki kalıpları bulmak, kararlar ve tahminler yapmamızı sağlayan "kuralları" öğrenmek veya durumlar veya uygulamalardaki faktörler arasında bağlantılar veya "ilişkiler" bulmakla ilgilidir.
Ücretsiz yazılımı edinin
Artık makine öğreniminin, bilgisayar yığınları, bulut depolama dağları ve amaca yönelik pahalı yazılımlarla dolu laboratuvarlarda yapıldığını düşünebilirsiniz. Haklısın ama bu aynı zamanda evde de yapabileceğin bir şey. Üstelik makul miktarda makine öğrenimi yazılımı ücretsiz olarak sunuluyor. "Hadoop" veya "R" gibi popüler örnekler, dağlar kadar veriyi işlemek için güçlü çerçeveler sağlar, ancak ilk seferde kullanımları biraz göz korkutucu olabilir. Ve Ford'a karşı Holden veya iOS'a karşı Android gibi, farklı yazılımların tutkulu destekçilerinin olduğu bir alandır.
Temel bilgileri öğrenmek için yaygın olarak kullanılan bir uygulama, Yeni Zelanda'daki Waikato Üniversitesi tarafından geliştirilen WEKA'dır (yeni sekmede açılır) . Hadoop gibi, Java programlama dili kullanılarak oluşturulmuştur, böylece herhangi bir Windows, Linux veya Mac OS X bilgisayarda çalıştırabilirsiniz. Mükemmel değil ama grafiksel kullanıcı arayüzü (GUI) kesinlikle yardımcı oluyor.
Makine öğrenimi nasıl çalışır?

Makine öğrenimi, öğrenmek istediğiniz bir durumu temsil eden "veri kümesi" ile başlar - bunu bir elektronik tablo olarak düşünün. Sütunlarda bir dizi ölçüm veya "öznitelik" bulunurken, her satır öğrenmek istediğiniz şeyin veya "kavramın" bir örneğini veya "durumunu" temsil eder.
Örneğin, diyabetin başlangıcına ilişkin göstergeler arıyorsak, bu özellikler hastanın vücut kitle indeksini (VKİ), kan şekeri düzeylerini ve diğer tıbbi faktörleri içerebilir. Her örnek, bir hastanın öznitelik kümesini içerecektir. Bu durumda, veri kümesi ayrıca hastanın diyabet geliştirip geliştirmediğini gösteren bir sonuç veya 'sınıf' özelliğine sahip olacaktır.
Tanı için başka bir hasta gelirse ve biz onların diyabet riski taşıyıp taşımadığını öğrenmek istiyorsak, makine öğrenimi, veri kümesi öğrenimine ve o kişinin ölçülen tıbbi özelliklerine dayanarak bu olasılığı tahmin etmeye yardımcı olacak kurallar geliştirebilir.
Kurallar neye benziyor?
TechRadar'da sevdiğimiz gerçekten harika araçlardan biri, bağlantılı işlevleri gerçekleştirmek için sosyal ağ hizmetlerini birleştiren bir program olan IFTTT'dir (yeni sekmede açılır) (Eğer Bu O Zaman Buysa). Adından da anlaşılacağı gibi, 'eğer bir olay olursa, o zaman git bir şeyler yap' şeklindeki basit 'eğer-o zaman' programlama deyimi üzerinde çalışır.
Makine öğrenimindeki temel kurallar aynı çizgidedir - X olayı meydana gelirse sonuç Y olur. Veya bu bir dizi olay olabilir - X, Y ve Z meydana gelirse sonuç A veya A, B ve C olur. .
Bu kurallar bize öğrenmek istediğimiz kavram hakkında bir şeyler söyler. Ancak kuralların bize ne söylediği kadar, ne kadar doğru oldukları da önemlidir. Kural doğruluğu, bize doğru sonucu vermesi için kurallara ne kadar güvenebileceğimizi gösterir.
Bazı kurallar mükemmeldir - her seferinde doğru cevabı alırlar, diğerleri umutsuz olabilir ve bazıları arada kalır. Ek zorluklar da vardır - 'fazla uydurma' olarak adlandırılan, bir dizi kuralın öğrenildikleri veri kümesi üzerinde mükemmel şekilde çalıştığı, ancak kendilerine verilen herhangi bir yeni örnek veya örnekte kötü performans gösterdiği durum. Tüm bunlar, makine öğreniminin ve onu kullanan veri bilimcilerin dikkate alması gereken şeylerdir.
Temel algoritmalar
Birçoğu oldukça karmaşık olan düzinelerce farklı makine öğrenimi işlevi veya 'algoritması' vardır. Ancak hızlı bir şekilde öğrenebileceğiniz 'ZeroR' ve 'OneR' adlı iki basit örnek var. Bunları göstermek için WEKA uygulamasını kullanacağız, ancak nasıl çalıştıklarını görmek için elle de hesaplayacağız.
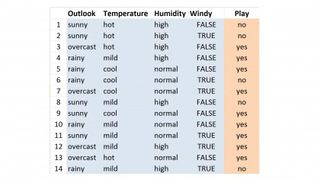
WEKA paketi, bir dizi örnek veri kümesi içerir; bunlardan biri, o sırada bir dizi hava olayı verildiğinde, belirli bir günde golf oynanıp oynanmadığının 14 örneğini içeren çok küçük bir 'hava durumu.nominal' veri kümesidir. Beş ölçü veya "özellik" vardır - görünüm, sıcaklık, nem, rüzgarlı ve oyun. Bu sonuncusu, o gün golf oynanıp oynanmadığını (evet) veya oynanmadığını (hayır) söyleyen çıktı veya 'sınıf' özelliğidir.
İçinde sıfırlama
ZeroR, dünyanın en basit veri madenciliği algoritmasıdır - çok basit olduğu için ona 'algoritma' demek biraz kaba olur, ancak herhangi bir uygun algoritmanın üzerine inşa etmeyi umacağı temel doğruluk seviyesini sağlar.
Şu şekilde çalışır: Yukarıdaki görüntüdeki hava durumu verilerini kontrol edin, o 'play' sınıfı özelliğine bakın ve 'evet' ve 'hayır' değerlerinin sayısını sayın. Dokuz 'evet' değeri ve beş 'hayır' değeri bulmalısınız. 'Evet' değerlerinin oranı 14 örnekten dokuzudur. Bu, başka bir örnek alırsak ve golf oynanıp oynanmayacağını tahmin etmek istersek, sadece 'evet' diyebilir ve 14'ün dokuzunda veya zamanın %64,2'sinde haklı olabiliriz demektir. Başka bir deyişle, ZeroR basitçe en popüler sınıf öznitelik değerini seçer.
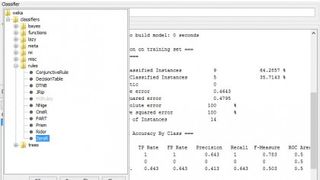
Bunu WEKA'da test edebilirsiniz – bilgisayarınızda Java Run-time Engine'in (JRE) yüklü olduğundan emin olun, ardından WEKA'yı indirin, kurun ve uygulamayı başlatın. Öğrenme penceresini başlatmak için 'Gezgin' simgesine tıklayın. WEKA, ARFF adlı değiştirilmiş bir CSV (virgülle ayrılmış değişken) formatı kullanır ve örnek veri setlerini /program files/weka-3-x/data alt klasöründe bulabilirsiniz. Explorer penceresinde Dosya Aç düğmesine tıklayın ve 'weather.nominal' veri kümesini seçin. Ardından, Sınıflandır sekmesine tıklayın ve Seç düğmesinin yanındaki Sınıflandırıcı metin kutusunda 'SıfırR' zaten gösterilmelidir. Sol taraftaki kontrol panelindeki 'Test Seçenekleri' altındaki 'Eğitim setini kullan'ın yanındaki radyo düğmesine tıklayın ve son olarak Başlat düğmesine basın.
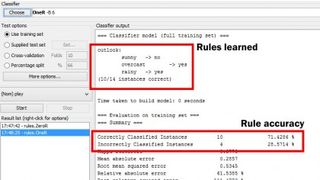
Neredeyse anında, Classifier Output penceresinde sonuçları alacaksınız. Aşağı kaydırın ve ZeroR varsayılanlarının 'evet' sınıf değerini ve daha sonra, yanında '9' ve '% 64,2857' gösteren 'Doğru Sınıflandırılmış Örnekler'i seçtiğini göreceksiniz. Sonuç olarak, WEKA daha önce yaptığımızın aynısını yaptı - 'evet' ve 'hayır' sınıf değerlerini saydı ve en yaygın olanı seçti.
Hepsine hükmedecek tek bir kural
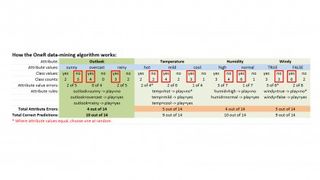
ZeroR, bu örnekte bize %64,2 temel düzeyde öğrenme doğruluğu veriyor, ancak bundan biraz daha iyisini yapmak güzel olurdu. İşte burada OneR algoritması devreye giriyor. Buna "sınıflandırma kuralı öğrenicisi" denir, çünkü bir eğitim veri kümesinden öğrendikleri göz önüne alındığında, gelecekteki bir örneğin sonucunu belirlememize veya "sınıflandırmamıza" izin veren kurallar üretir.
Yukarıdaki OneR tablosuna bakarsanız, nasıl çalıştığını görebilirsiniz - her hava durumu veri kümesi özelliğinin az sayıda olası değeri vardır. Outlook için "güneşli", "bulutlu" ve "yağmurlu" şeklindedir. Sıcaklık için 'sıcak', 'ılımlı' ve 'soğuk' vb. Her özellik değeri için ayrı bir liste oluşturuyoruz ve ardından aldığımız 'evet' ve 'hayır' sonuçlarının sayısını not ederek her değerin bir örnekte kaç kez geçtiğini sayıyoruz.
Örneğin, 14 örneği incelerken, görünümün güneşli olduğu beş durumda bize iki 'evet' ve üç 'hayır' sonucu verdiğini görebilirsiniz. Aynı şekilde, 'görünüm = bulutlu', dört 'evet' oyu alır ve sıfır 'hayır' sonucu alır. Daha sonra diğer tüm nitelikler için de aynısını yaparız.
Ardından, hataları sayıyoruz - bunlar her özellik değeri için daha küçük sayılardır, bu nedenle yine "görünüm = güneşli" için "evet" sayısı yalnızca ikidir; "görünüm = bulutlu" için "hayır" sayısı sıfırdır, "görünüm = yağmurlu" için iki ve böyle devam eder. Tablodaki kırmızı kutular, her özellik değeri için en popüler sınıf değerlerini gösterir ve bunlardan ilk 'Outlook' kuralları grubumuzu oluştururuz:
Görünüm = güneşli -> Oynat = hayır Görünüm = bulutlu -> Oynat = evet Görünüm = yağmurlu -> Oynat = hayır
Again, we do likewise for the other attributes. What we're doing is taking the most popular class value for each attribute value and assigning it to that attribute-value pair to make a rule, so for this example, outlook being 'sunny' leads to play being 'no' and so on. Next, we repeat this for each of the other three attributes. After that, we add up those 'error' counts for each attribute value, so Outlook is 2 + 0 + 2 totaling 4 out of 14 (4/14). For temperature, we get 5/14, 4/14 for Humidity and 5/14 for Windy.
Now, we choose the attribute with the smallest error count. Since in this example we have two attributes with error count of 4 out of 14 (Outlook and Humidity), you can choose either - we've gone with the first one, the 'Outlook' attribute ruleset above.
This now becomes our 'OneR' (one-rule) classification rule set. Using this rule on the training dataset, it correctly predicts 10 out of 14 instances or just under 71.5%. Remember, ZeroR gave us 64.2%, so OneR gains us greater accuracy, which is what we want.
Using the new rule
Let's say we're given a new instance – the outlook is rainy, temperature is mild, humidity is high and windy is false. What is 'play' – will golf be played or not? Our OneR rule says if the outlook is rainy, play is 'no', so that's our answer – for this instance, it's very likely (about 71.5%) there's no golf happening today.
Seç düğmesine tıklayarak ve 'Kurallar' listesinden 'OneR'yi seçerek WEKA'da OneR sınıflandırma testini çalıştırın. Başlat düğmesine basın ve aynı kural listesini, onda doğru sınıflandırılmış örnek sayısını ve 71.4286 yüzdesini göreceksiniz. Bu tam olarak daha önce hesapladığımız şeydi.
Buzdağının zirvesi
Elbette, hava olaylarına dayanarak hangi günlerde golf oynanacağını tahmin ederek milyonlar kazanmayacağız veya dünyayı kurtarmayacağız, ancak mevcut hava koşullarının büyük bir dolu fırtınasına neden olup olmayacağını belirleyen bir meteorologsanız, veri madenciliği teknikleri ( Kuşkusuz burada gördüğümüzden daha karmaşık) bu cevaplara yardımcı olabilir.
Makine öğrenimi, etrafımızı saran aşırı bilgi yüklemesini "verilerle ölüm" anlamlandırmayı amaçlayan, dünya çapında bilgisayar araştırmalarında patlama yaşayan bir alandır. Burada yüzeyi zar zor çizdik, ancak bir dahaki sefere internete girdiğinizde veya alışverişe gittiğinizde, ürettiğimiz verilere ne olduğu hakkında daha iyi bir fikir edineceğinizi umarız.